
A recent article about Paul Allen’s project Alexandria mentions the need for computers being able to have common sense. This means computers reaching somewhat human level cognition, which is a super ambitious goal. This level of achievement is most likely infeasible in the short run, and funding judgments for this goal is encouraged by the availability of super computers and vast amount of data. However, the assessment of this goal and the possible routes to success require us to define a measurable (or perceivable) scale. Hence, let’s start defining such a scale.
THE SCALE OF COMMON SENSE AI
The easiest scale to follow this argument is the basic definitions of data, information, knowledge, and logic as shown here in the figure below. Detection of the difference among data creates information. Same hierarchy applies to knowledge, logic, and common sense reasoning. If there is no difference detected, there can be no information, knowledge, logic, or common sense reasoning. This is the very basic premise of processing intelligence. For computers to operate at the “common sense” level, they are required to resolve (1) common sense resoning from logic, (2) logic from available knowledge, (3) knowledge from available information, and (4) information from available data. The question is how can we shorten this path for a feasible solution for common sense reasoning in the foreseeable future?

KNOWLEDGE-SCIENCE, THE SHORTER ROUTE
Methods of data science, such as deep learning, are useful for anaylzing data to extract new information. These methods can sometimes go one step further to produce knowledge with limitations (For example, stock market analysis using data-driven methods can never justify the knowledge produced). There is a natural barrier of conversion from information to knowledge by sheer data analysis. Knowledge science is an entirely different realm. The difference between data science and knowledge science is as striking as the difference beteen Newtonian physics versus Quantum physics.
The challenge of knowledge science is to deploy correct models of knowledge, whereas data science crunches numbers without assuming a model.
The attractiveness of “no model” in deep learning, for example, causes a misconception such that it can be applied to higher domains (i.e., CNN applied to any problem). One particular direction is natural languages where tensor flow and vectorized words are assumed to cross that barier. One of my earlier articles titled “Why Deep Learning and NLP don’t Get Along Well?” explain why this is nothing but wishfull thinking.
As shown in the figure above, knowledge-driven machine learning will undoubtedly be the shorter path to reach common sense reasoning. Because the existing knowledge (millions of books for example) can be processed by a computer just like reading them to learn. Here is another article, titled “Can Machine Learning Use Knowledge instead of Data?” that sheds light to this subject.
KNOWLEDGE-DRIVEN MACHINE LEARNING (LEARNING BY READING)
Knowledge-driven approach does not treat sentences in natural language as data. Instead, it assumes them as part of its initial model. The basic premise is that the initial model assumed for knowledge representation can be corrected iteratively as more sentences are processed. This hypothesis is supported by our own human experiences as our understanding improves by reading more books.
The idea of lifting knowledge from a source curated by a human experts (authors), and implanting to a computer is, in one sense, similar to cloning knowledge. Hence, the method is called Deep Cloning, and explained in this article titled “Deep Cloning vs Deep Learning“.
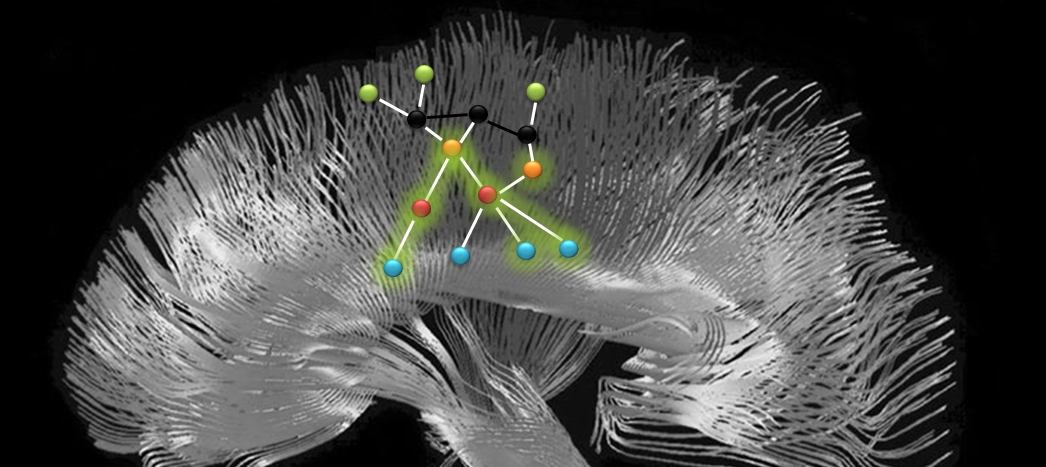
The figure below shows one of our experiments with deep cloning for logic resolution. The system resolves the question “Is Mike in good shape?” by following a path through its knowledge representation from the sentences acquired earlier. As more sentences learned, the logic improves, and it may strengthen of reverse its conclusion. This demo will be open to public in coming months.

COMMON SENSE AI
It will clearly be a very long path for implanting common sense reasoning to a computer. The knowledge-driven methods offer a shorter path to reach the goal while subject to more challenging and creative solutions.
If we can make computers read and learn like we do, then there is a good chance to expect higher level cognitive functions from them in the near future.
__________
This article is brought to you by exClone.com, a chatbot technology provider.
Join CHATBOTS group in linkedin.
Join our experiments, chat with Vera about exClone.
Try free (no cc required) of our Cloning Platform via Linkedin access.
You can follow exClone in Facebook, and in LinkedIn.