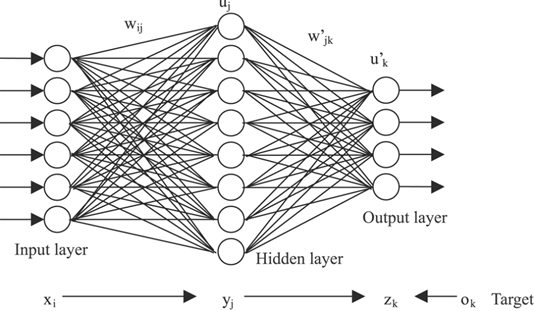
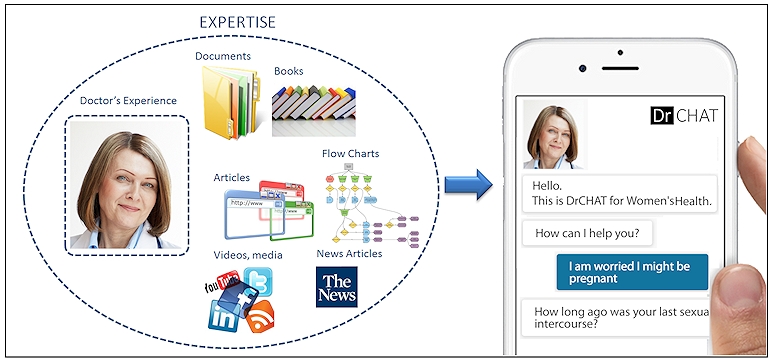
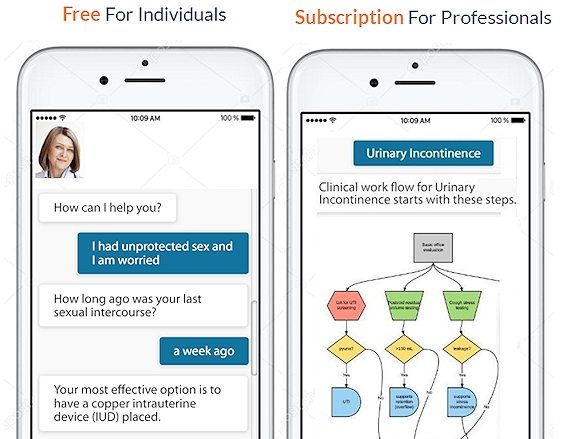
If you like listening to a podcast while taking a walk, you are one of millions of people who enjoy doing this every day. Now, you can experience something totally new: interactive AI podcasting. Instead of being a passive listener, you control the flow and use of the content. You curate your own podcast experience.
What is an Interactive AI Podcast?
Interactive AI podcasts allow you to:
- Have dialogue like talking with an assistant
- Skip to the next story or next subject matter
- Ask questions/get answers about something you heard in the story
- Repeat sections of importance or pause for thinking
- Express your opinion and provide feedback simply by talking
- See images and videos accompanying the storyline
Interactive AI podcasts allow the content creator to:
- Have the AI computer voice the story automatically
- Learn where listeners skipped and disliked content
- Understand what questions were posed, and what engaged listeners
- Receive listener opinions and feedback
- Overcome the limitations of conventional podcasts as described above
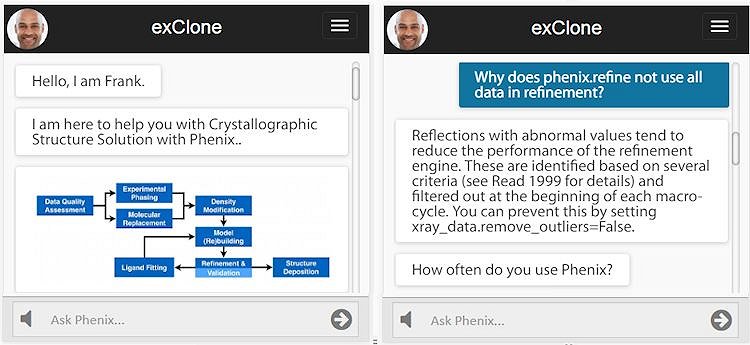
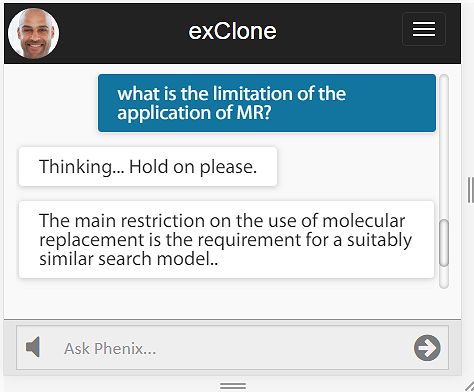
Try Dr. Margo, Interactive AI Podcasting, Subject: Coronavirus
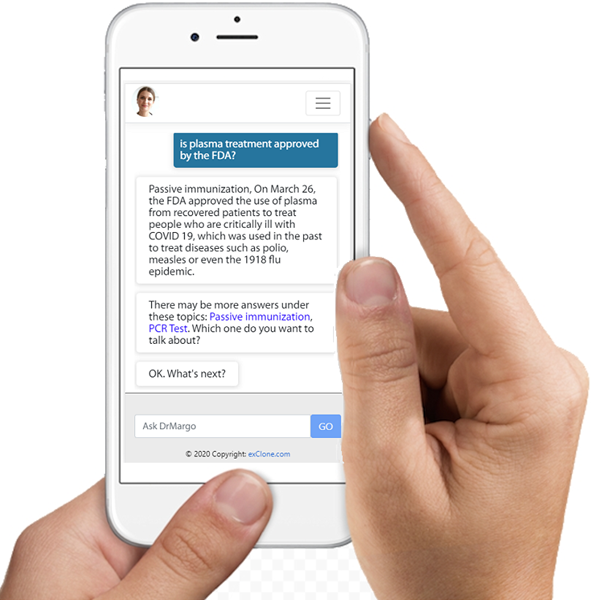
Try the BETA version of interactive podcasting (links below)! The best experience is designed for the mobile use (wearing headphones. The link to download mobile app iOS is here, and Android is here. Mobile apps have complete voice interaction – say or click on “Podcast” to start it, then say “stop podcast” to end it. The app also provides images and videos accompanying the story. Use headphones!
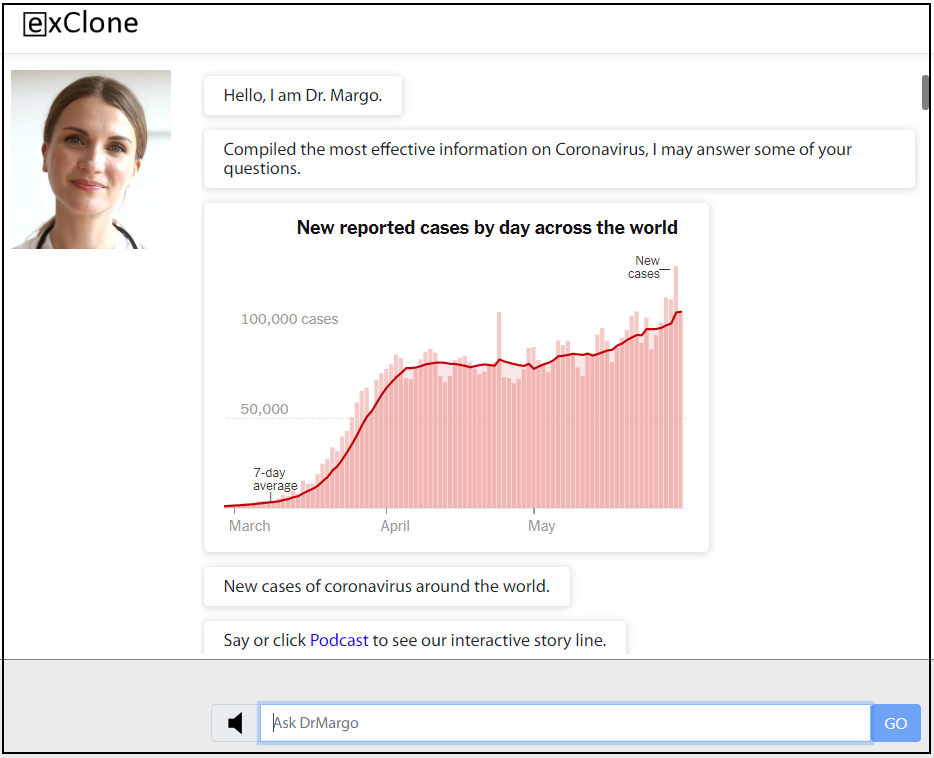
The link for Dr. Margo is here where you can test her using the Web browser. Make sure to click on the speaker button to hear the podcast (the button is at the bottom inside the search box.) Note that the Web browser version does not take your voice, it only takes your typing. Dr. Margo’s virtual expert will continue servicing after the podcast with questions and further information about the coronavirus.
A New Approach to Education and Corporate Training
Podcast can be an effective educational tool. Now that is enhanced by interactive AI control. Most importantly, the listener can talk to it just as talking to a teacher or a tutor. Once dialogue is introduced, the most important element of learning starts to emerge.
The beauty of mobile phone technology is to connect us to an information source via headphones while we are busy with mundane things in life. Working out, cycling, walking, cleaning, gardening, etc. all may be accompanied by a podcast, as we multi-task and expand our potential. Interactive AI Podcasts allows the listener to pause, repeat, ask a question, or skip ahead. These are all basic functions of learning, which are further enhanced by images and videos.
Turn Your Documents into an AI Podcast
This new technology was created by exClone, which now offers its platform to you to try Interactive AI Podcasting. Click here to request a demo. The platform will be accessible by simple subscription soon.
Happy interactive podcasting!
_________________________________________________________
This article is brought to you by exClone.
Request a Demo from exClone
Join CHATBOTS group in LinkedIn.
You can follow exClone in Facebook, and in LinkedIn.
exClone App (iOS) Ecosystem of virtual experts (beta)
exClone App (Android) Ecosystem of virtual experts (beta)