
Machine Learning (ML) field is defined by most people to be exclusively a field of data science, which is incorrect in principle. The main goal is to make computers perform cognitive skills similar to human brain and to immitate how human brain learns and thinks. Why use data only? Isn’t most of our learnings based on knowledge consumption?
Human brain learns mostly from knowledge, not from data!
As a result, we need machine learning methods that use knowledge directly. This area of research has not been explored as much as its data-driven counterpart (deep learning) because of the challenge of Knowledge Representation (KR) and the difficulty of computerized ontology creation.
KR methods such as semantic nets and logico-linguistic modeling have a long history of R&D using static/given knowledge but not in the context of “learning”. So, the question is how can we extend KR methods into a “learning” method? This brings us to the new idea of deep cloning where KR is molded into a neural-network-like structure poised for learning by reading.
Can Computers Learn by Reading?

Knowledge-based learning methods make it possible for computers to learn by reading similar to how we educate ourselves. Once a deep cloning system is set, then a computer can start reading books (text) to learn a subject and answer questions about it. The trade off is between the difficulty of ontological (knowledge-based) learning versus the advantages of independence from training large data (corpus) and dealing with issues like convergence and generalization.
Advantages of Knowledge-based Learning
There are a number of advantages of this approach in comparison to data-driven methods as outlined below:
- One-shot Machine Learning: Since knowledge does not require a supervised reference point, learning becomes one-shot machine learning devoid of convergence problems encountered in deep learning.
- Not Stuck in the Past: Data-driven models require data collected from the past experiences. This makes them vulnerable in application to new things (i.e., new car, new plane, new drug, new house, new neighborhood, new disaster.) Knowledge-based systems are not biased by the past, and can employ new knowledge immediately.
- Knowledge is Less Limited than Data: Availability and abundance of data do not guarantee its completeness, and data can still be limited in explain the process it comes from. Weather prediction is a good example. Knowledge, on the other hand, represents the best data experience available.
Fundamental Differences
In processing natural language and representing knowledge (after reading a text), deep cloning network (shown on the left) is comprised of layers with different objectives and different neuron functions. In contrast, deep learning (shown on the right) is a homogenous architecture of neurons dedicated to minimize the error at the output in a supervised mode of learning. Despite variations of deep learning, no neuron activity is designated for any linguistic role.
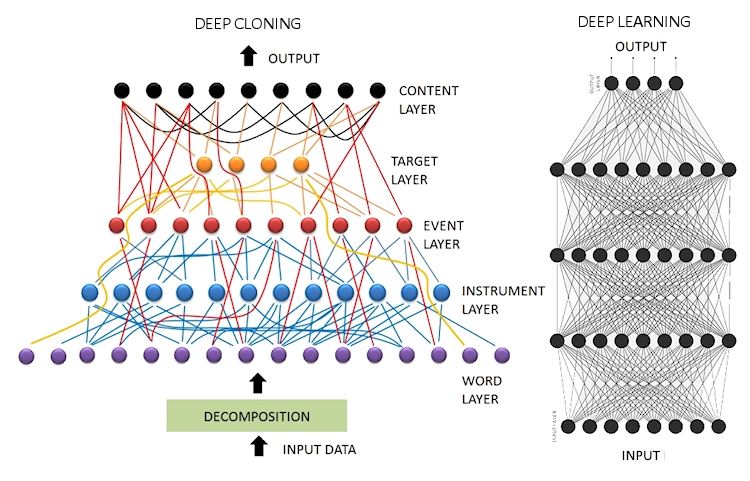
Knowledge representation on the left can be a one-shot process using only the text of the knowledge whereas learning on the right requires long training cycles using corpus way larger than what is needed on the left.
Answering Questions
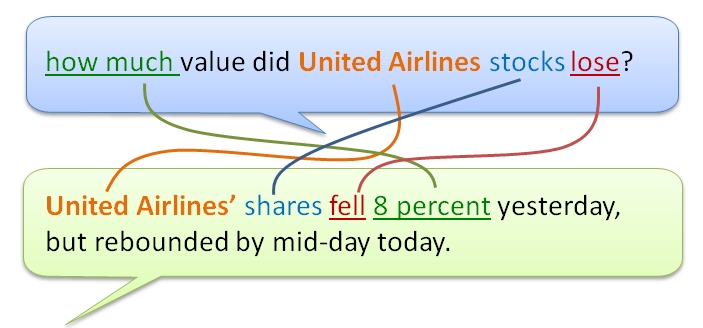
Knowledge-based machine learning can answer questions from the content it learned with utmost precision using the ontological connections shown in the network picture above. Shown aboveis a hypothetical case, where a question presented to the network finds its most relevant answer using those connections. In case of partial connections, the network puts more emphasis on target, event, and instrument (in this order) and produces answers with an accuracy score. Based on the type of application, a threshold can be set to declare “no answer” if the best scoring sentence is below the threshold. With such a capability, the chatbot becomes self-aware of its performance, and can report how well it did in answering questions. This can be further expanded to social learning where chatbots can ask for feedback to learn how to answer particular questions.
Knowledge Breeding

More impressive than answering questions, deep cloning machine learning can breed new knowledge from the content it learned as shown on the right. This is logic resolution using existing knowledge to produce possible new knowledge using the ontological connections. Obviously, breeding new knowledge is one of the most exciting aspects of learning algorithms that are not as straight forward as it looks when using data-driven models such as deep learning. One of the advantages of knowledge-driven machine learning is that the “new knowledge” is transparent (can be verified by human inspection) whereas the same cannot be said for data-driven deep learning.
__________
This article is brought to you by exClone, a chatbot technology provider.
Chat with Vera about exClone.
Try free (no cc required) of our Cloning Platform via Linkedin access.
Join CHATBOTS group in linkedin.
You can follow exClone in Facebook, and in LinkedIn.
__________
#chatbot #chatbots #AI #artificialintelligence #ConversationalAI #Virtualassistants #bots #machinelearning #NLP #DL #deeplearning #deepcloning





